





In this experiment, we aimed to understand how users currently interact with how-to videos for physical tasks. Specifically, to understand different types of navigation objectives and user intentions, we examined when users broke away from their tasks and actively control the video using a conventional mouse-based video navigation interface like YouTube (on the right).
Pace Control Pause: The most common type of pause was a pause to gain more time. This happens when the user understands the video content but fails to match the pace of the video.
Content Alignment Pause: The second type of pause is a pause to compare what’s in the video with what’s in the hands of the user. This pause precedes the user checking to make sure that their state is similar to that of the video.
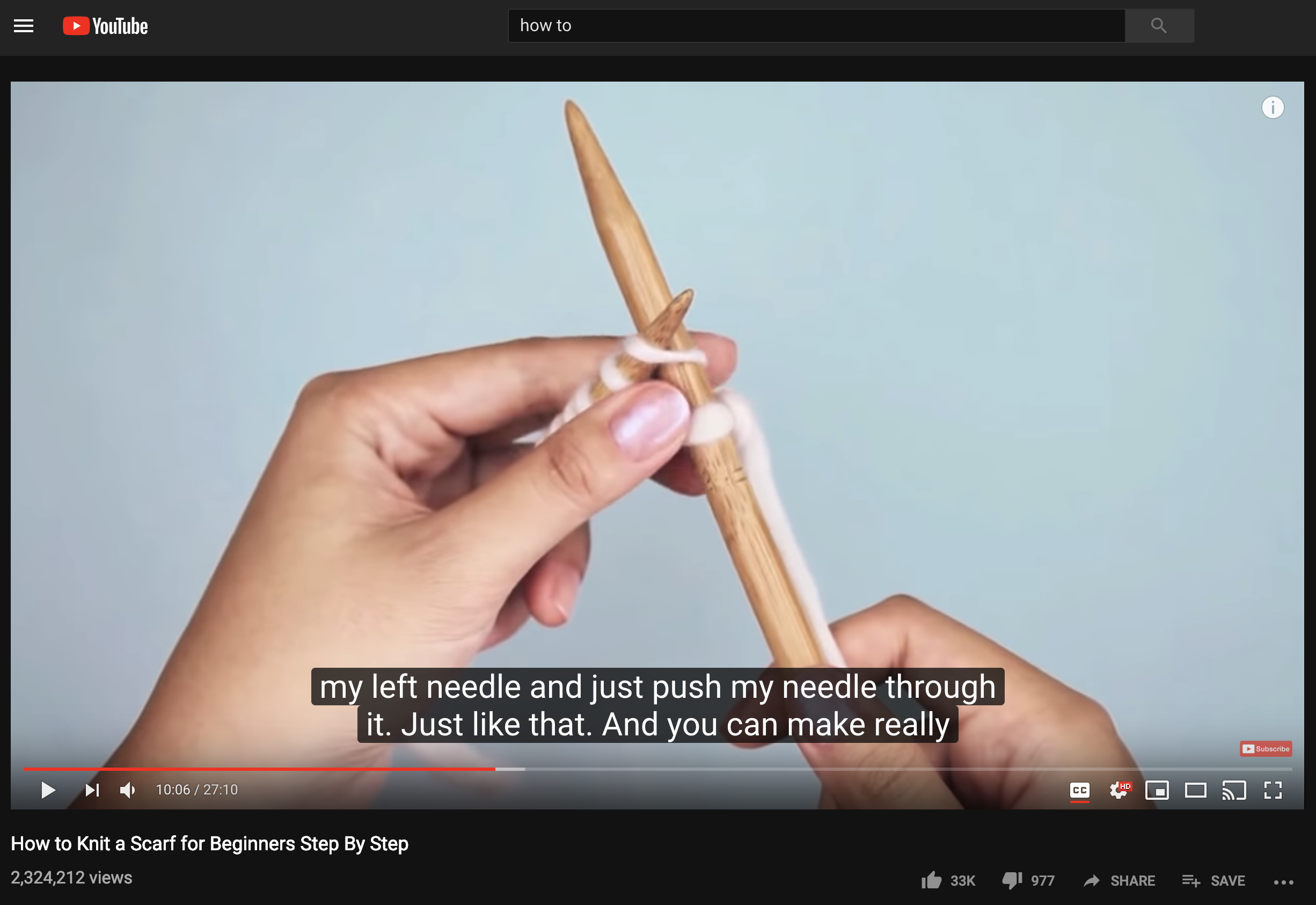
Video Control Pause: The final type of pause we observed is a pause for further video control. In this case, the user pauses the video and searches for the next navigation target point on the timeline by either guess-clicking, or scrubbing and examining the thumbnails.
Reference Jump: The first type of jump we observed is a reference jump. In this case, the user jumps backwards in the video to remind themselves of something they saw in the past.
Replay Jump: A replay jump is a different form of backward jump, where the user wants to re-watch a segment of the video again. This jump happens when the user needs to get a better understanding, clarify a possible mistake, or to assure that the current understanding is correct. This jump if often followed by a play or a pause interaction.
Skip Jump: A skip jump is a type of forward jump where the user wants to skip content that is less interesting, like the introduction of the channel or the personal life of theYouTuber.
Peek Jump:The second type of forward jump is a peek jump, where the user wants to skip ahead to see what the user should expect after performing one or a number of steps. This happens when users want to check the intermediate or the final result in order to prepare and also check if the user is on the right track.
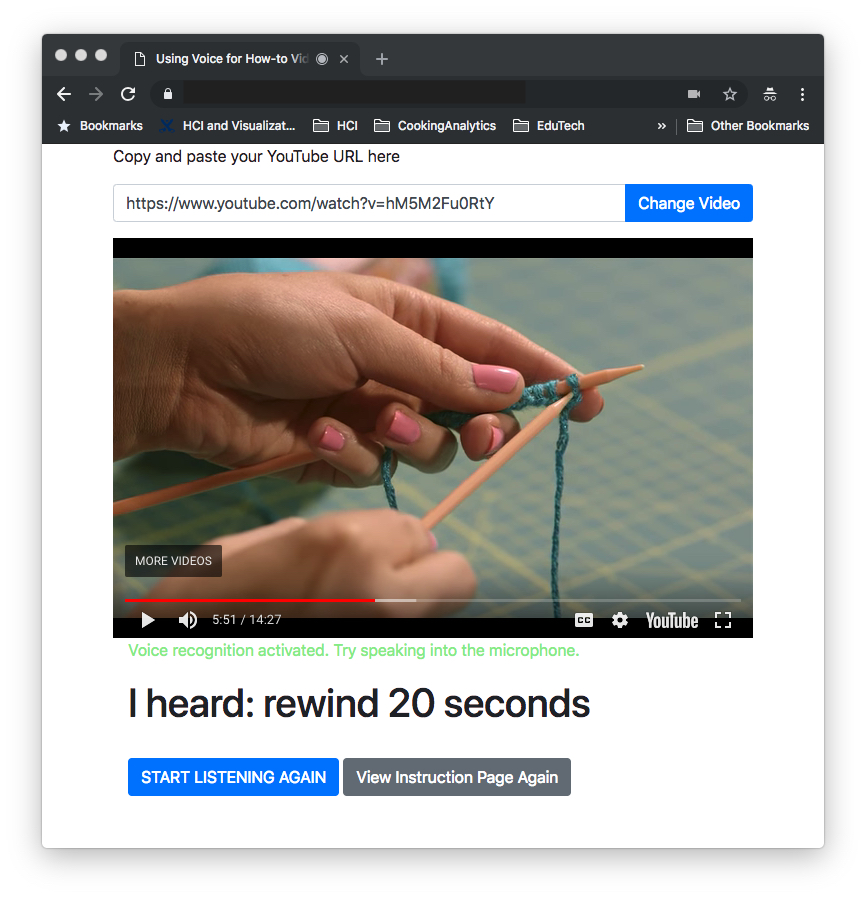
Results of our first study show that people often stop and jump within the videos, which requires frequent context switches. To understand what differences might be observed in users’ thoughts and preferences of voice interactions in navigating how-to videos, we built a voice-enabled video player as a research probe. This research probe served as a “tools for design and understanding” not a prototype interface to suggest new interaction techniques. We used our research probe as an apparatus to observe and elicit similarities and differences in user behavior in relation to the different types of pauses and jumps observed with a traditional mouse-based interface.
Our research probe (on the left) allows users to select a YouTube video of their choice and control it with voice. The interface also indicates when it is listening and transcribes commands in real time to provide visual feedback to the user. For example, “I heard: rewind 20 seconds”. We also observed that users use the word “stop” to indicate a higher sense of urgency, or a need to navigate to a very specific point in the video.
Participants found the concept of using voice to navigate how-to videos useful for their tasks. We also noticed users would “stop” or “pause” the video before jumps a lot more often while using voice user interfaces. Jumps with specific references like “go back 20 seconds” is dependent on both the current position and the target, and without the pause the current position would keep changing, resulting inconveniences to adjust the interval or make multiple subsequent jumps. With the mouse interactions, in contrast, users are only specifying the target position and not the origin.
From the previous study, we learned that users’ navigation intents affect their linguistic choices for command utterances. We also observed that commonly supported voice commands are limited to simple words, that it can be difficult for users to express their intents with a restrictive command space, and that it is difficult for systems to understand the intents. For example, different backward jump intents for “stop” and “pause” can only be understood in context of other commands before and after the stop, specifically analyzing preceding and succeeding commands and user goals, which is impractical in application settings where users need systems to understand the user intents in real time.
To inform how to disambiguate voice commands and corresponding user intents for navigating how-to videos, we conducted a Wizard-of-Oz experiment to learn how users would naturally converse for video navigation in the absence of these constraints.
Because of the sequential nature of the video (there is the concept of an unknown future), users often make a guess to navigate forward in the video, or they have to watch less relevant or less interesting segments.
When participants used a specific time interval for jumps, it often required multiple adjustments to navigate to the target even when the participant had a good sense of where the target was. In this case, command parsing delays become an important user interface limitation.
Our study and interview results highlight the challenges, opportunities, and user expectations of using voice interfaces for video tutorials. We first summarize the user challenges of adapting to a VUI from a GUI when learning physical tasks with video tutorials. We then summarize how our research methodology of designing a series of experiments in progression can be extended to designing VUI for other applications and domains.
Mouse vs Voice. We found voice interfaces require an initial pause while issuing subsequent commands. For example, when using voice input in Study 2, users issued a pause command before every rewind command. In contrast, when using the traditional mouse interface, users never paused the video before skipping to another point. We think this is due to the time it takes for the user to speak the voice command and for the system to process it. Also, the target is directly specified with mouse (or touch) but with voice the target is often specified relative to the current position of the video. For example, if the user does not pause the video before jumping, the original reference keeps moving, and the interval they had thought of will not get them to the point they intended. As a result, the larger consequence is that voice-based interactions require more steps to achieve the same objective (i.e., pause + jump) than mouse-based interactions do (i.e., click).
Uncertainty from Unseen Content. When trying to navigate a video tutorial using voice, users make more concrete references to the past, whereas users have challenges describing later part of the video. For traditional video interfaces, scrubbing and clicking around are often used a solution to quickly peeking into the future. However, for voice interfaces, such a solution does not exist yet. Handling this uncertainty is an important design issue which would improve the usability of voice interactions for videos. Recognition of Speech Input and Command Learnability. While the concept of using voice to navigate how-to videos is generally welcomed, participants also reported well-known problems of voice user interfaces. Speech recognition does not always work as expected, especially if users have accents or are in a noisy environment. In Study 2, nine participants also reported difficulty in figuring out the available commands. All participants showed frustration when the system did not respond to their command. Usability of VUI suffers due to relatively poor recognition, poor learnability and discoverability of available commands, and lack of feedback.
Based on our findings and understanding from the three studies, we propose the following recommendations for designing voice based navigation for how-to videos.
Support sequence expansions and command queues as both are strategies users often use. For example, supporting users to perform a single command multiple times in a row by recognizing “again” following “go back 5 seconds”, and supporting users to place multiple commands in one utterance like “go to 2 minutes and 4 second mark and pause” would be useful.
Users often need multiple tries to find the intended navigation target. It is because a) what users remember can be different from the part they are looking for or vice versa, b) sometimes users don’t remember, and c) sometimes users remember but don’t know the exact vocabulary like the names of knitting techniques and tools. Good examples are support for descriptive commands and keyword search in transcripts.
Designing voice commands for how-to videos is not about supporting a single command, but understanding the higher level user intent behind the utterance is crucial. We identified all seven interaction intents (pace control pause, content alignment pause, video control pause, reference jump, replay jump, skip jump, and peek jump) that can be supported. One possible solution in distinguishing them is to set up the command vocabulary such that each intent has its unique keyword.
@inproceedings{Chang:2019:DVB:3290605.3300931,
author = {Chang, Minsuk and Truong, Anh and Wang, Oliver and Agrawala, Maneesh and Kim, Juho},
title = {How to Design Voice Based Navigation for How-To Videos},
booktitle = {Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems},
series = {CHI '19},
year = {2019},
isbn = {978-1-4503-5970-2},
location = {Glasgow, Scotland Uk},
pages = {701:1--701:11},
articleno = {701},
numpages = {11},
url = {http://doi.acm.org/10.1145/3290605.3300931},
doi = {10.1145/3290605.3300931},
acmid = {3300931},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {conversational interaction, how-to videos, video navigation, video tutorials, voice user interface},
}